
Temperature 与 Top-p 学习笔记
用过大语言模型 API 的人大概都见过这两个参数——Temperature 和 Top-p。调一下,输出变了;再调一下,又变了。但到底怎么回事,很多人说不清。
模型每次都在做选择题
模型每生成一个 token,本质上是在做一道选择题。它会给词表里每一个词打分,这个分数叫 logits。分越高,这个词被选中的可能越大。
但 logits 是原始分数,不能直接当概率用,需要过一道 softmax 才能归一化。之后的流程大概长这样:
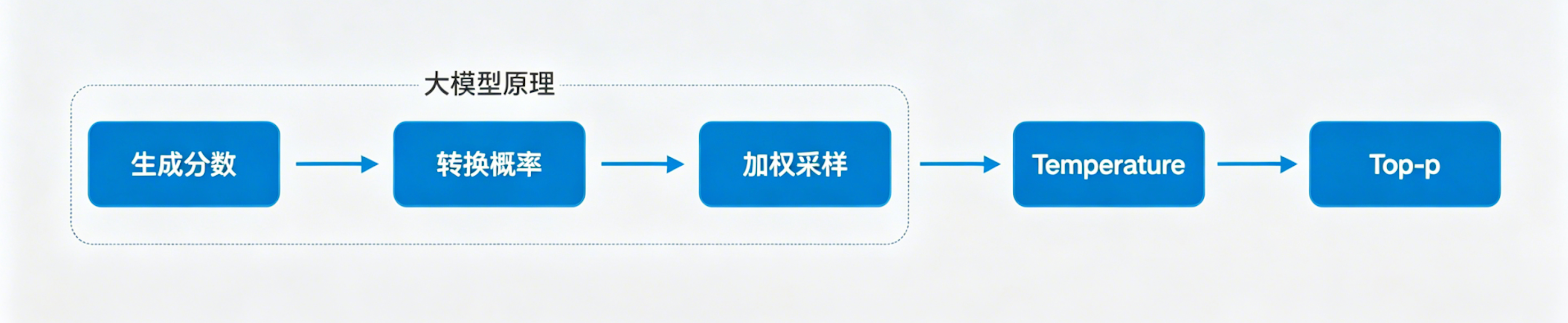
Temperature 和 Top-p 就是流程图后半段那两个”旋钮”,各自用不同的方式控制”从概率里怎么挑词”。
Temperature:把分数的差距拉开或压平
Temperature 作用在 softmax 之前,直接改 logits 的分布:
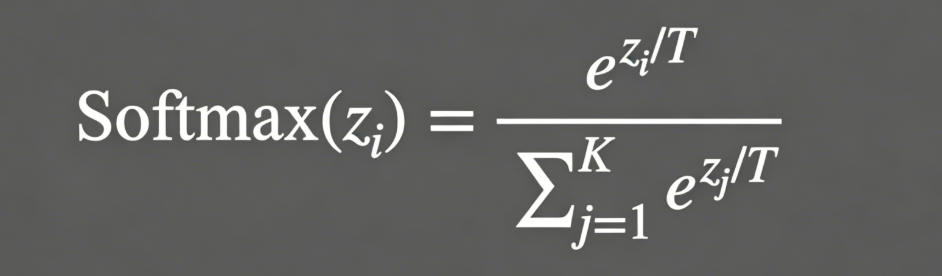
公式里的 T 就是 temperature 值,它被用来除每个 logit。
T = 1 的时候,原始分布不变,该大概率就大概率,该小概率就小概率。
T < 1(比如 0.3),logits 之间的差距被放大。原来得分 5 和 3 的两个词,除以 0.3 之后变成 16.7 和 10,差距从 2 拉到了 6.7。高分的词更突出,选它的概率更高,输出更”确定”、更保守。
T > 1 反过来,logits 差距被压缩,高分的没那么突出了,低分的也有机会,输出更发散。
T = 0 是极端情况——实际上就是取 argmax,直接选得分最高的那个词,没有任何随机性。
说到底,temperature 控制的就是”模型有多敢冒险”。
Top-p:按累计概率截断
Top-p(也叫 nucleus sampling)走的是另一条路。它不动概率分布,而是在采样阶段做筛选。
做法很直觉:把所有词按概率从高到低排好,从第一个开始累加概率,加到 p 就停。只从这个范围内采样,之外的词全部扔掉。
举个例子,p = 0.9 的时候,排在前面的几个词加起来已经到 90% 了,剩下 10% 的词直接排除。好处是既能保住多样性,又不会选到特别离谱的词。p = 0.1 基本只从概率最高的那一两个词里挑,p = 1 就是所有词都在池子里。
以前还有个 Top-K,怎么不见了
Top-K 的逻辑很简单:不管概率分布长什么样,永远只从概率最高的 K 个词里选。K=50 就取前 50,K=10 就取前 10。
问题在于 K 是固定的,不会根据分布的形状自适应。
假设 K = 50。模型对下一个词非常确定,第一名概率 0.95,第二名 0.02,后面 48 个词加起来不到 0.03——Top-K 还是硬把这 50 个词全放进候选池,强行引入了一堆不该出现的选项。反过来,模型很纠结,概率均匀分散在前 200 个词上,Top-K 只取前 50 个,砍掉了一半合理的候选。
该保守的时候不够保守,该开放的时候又不够开放。
Top-p 解决的就是这个问题。它不按个数截,按概率截。模型确定的时候,前两三个词概率就累加到 0.9 了,候选池自然就小;模型不确定的时候,要往后排很远才能凑够 0.9,候选池自然就大。相当于动态调节了”池子大小”。
Top-K 没有完全消失,有些框架还保留着当后备选项,或者跟 Top-p 叠加使用(先 Top-K 粗筛,再 Top-p 精筛)。但主流用法里单独用 Top-K 的确实很少了。
两个能一起调吗
可以,但 OpenAI 的文档原话说得挺直白:改了 temperature 就别动 top-p,反过来也一样。两个参数同时调会互相干扰,很难预测最终效果。实际使用中 temperature 更常见,因为”我要更确定”还是”我要更有创意”更好理解。
temperature = 0,为什么结果还是不一样
这大概是大家最困惑的一点。temperature = 0 意味着 argmax,每次都选概率最高的词,理论上输出应该完全一样。但跑两次同样的 prompt,输出确实可能不同。
背后是工程实现的问题。
模型前向传播涉及大量矩阵运算,GPU 为了性能会做并行计算。并行计算的累加顺序不固定——先算 A+B 再加 C,跟先算 B+C 再加 A,在浮点精度下结果会有微小差异。单个 token 上这点差异几乎看不见,但自回归生成是一环扣一环的,第 10 个 token 的输入依赖第 9 个 token 的输出。误差累积到一定程度,当两个候选 token 的 logit 非常接近时,浮点误差可能导致排序翻转——这次 argmax 选了 A,下次选了 B,之后的生成轨迹就彻底分叉了。
KV cache 和推理优化也会带来微小差异。一些框架(比如 vLLM)在 batch 处理时对注意力计算做近似优化,不同运行间数值可能有差别。跑在多卡或分布式环境上就更不用说了,通信和同步本身就引入不确定性。
一句话:temperature = 0 在数学上是确定性的,但工程上做不到绝对确定。浮点精度和并行计算把”完全可重复”的理想状态打破了。
需要严格可复现的话,可以固定随机种子、禁用并行优化(会变慢)、或者用 CPU 推理。不过对大多数场景,这点差异可以忽略。
实际怎么选参数
几个经验值供参考:
- 需要稳定的输出(代码生成、事实问答、格式化提取):temperature 0-0.3,top-p 不用管或设 0.9
- 需要平衡质量和多样性(通用对话、文章起草):temperature 0.5-0.7
- 需要创造力(头脑风暴、创意写作):temperature 0.8-1.2,可以配合 top-p 0.9-0.95
没有万能参数,看场景调。